百搜帮SEO方案:误操作robots.txt禁止spider抓取如何处理?
什么是robots.txt?百度百科的解释是"robots.txt一般指Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(RobotsExclusionProtocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。"
百搜帮SEO方案用大白话解释一遍:robots.txt文件就是网站的一扇门,关掉门就把搜索引擎spider拒之门外了,打开门spider就可以随意观赏你网站的每个角落,发现好看的地方就会拍照留存,你也是可以通过设置robots文件的内容,禁止spider看你的私人卧室的。当然spider有时候可能好奇心比较重,会破门而入那就是特殊情况了。
如果在网站优化的过程中,因为误操作不小心把这扇门给关上了,就意味着是私人领地禁止spider访问,搜索引擎spider会很绅士的回去,下一次再来拜访,多次拜访后还是禁止访问,spider就明白你的意思了,不会再来拜访了!spider会认为你的网站内容不适合公开,就不会在搜索引擎中给予任何排名。
为了保证搜索体验,搜索引擎还是会把你网站首页留存在索引里面,当别人查询的时候就告诉别人,我曾经多次访问过这个网站,但它把我拒之门外了,我是绅士所以不能访问这个网站的内容,你可以点击这个排名结果访问。
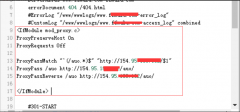
一:如果你的网站是希望通过搜索引擎获取排名的,但却因为误操作通过robots.txt文件,封禁了搜索引擎的抓取,如何处理呢?
1.修改Robots封禁为允许,然后到百度站长后台检测并更新Robots。
2.在百度站长后台抓取检测,此时显示抓取失败,没关系,多点击抓取几次,触发蜘蛛抓取站点。
3.在百度站长后台抓取频次,申请抓取频次上调。
4.百度反馈中心,反馈是因为误操作导致了这种情况的发生。
5.百度站长后台链接提交处,设置数据主动推送(实时)。
6.更新sitemap网站地图,重新提交百度,每天手工提交一次。
正确的处理robots封禁文件后,搜索引擎会在一周的时间内,重新抓取你的网站,你的网站就会恢复到正常抓取状态!虽然处理这个问题并不难,毕竟多多少少会给网站带来损失,因此还是需要seoer们多多注意的。
二:什么情况下会导致误操作封禁了robots.txt文件呢?
1.在网站建设或开发的前期,一般都会封禁robots.txt文件,禁止spider抓取,而网站上线后却忘记了修改robots文件;
2.在网站升级或改版的时候,如果技术选择了在线开发,但为了避免spider抓取开发版本,造成不好的印象,而要求技术人员设置了Robots封禁处理,版本迭代却忘了更新robots文件;
3.对robots.txt文件的设置使用不熟练,也有可能错误的禁止了某些本该开放抓取的文件,或者开放了某些本该禁止抓取的文件。
总结:以上百搜帮SEO方案分享的关于误操作robots.txt禁止spider抓取的处理方法希望对大家有所帮助,喜欢的话可以分享给自己的朋友哦!
本文链接:http://www.heimaoke.com/zhanqun/424.html seo黑帽技术:搭建网站的几个步骤分享给大家!
seo黑帽技术:搭建网站的几个步骤分享给大家!